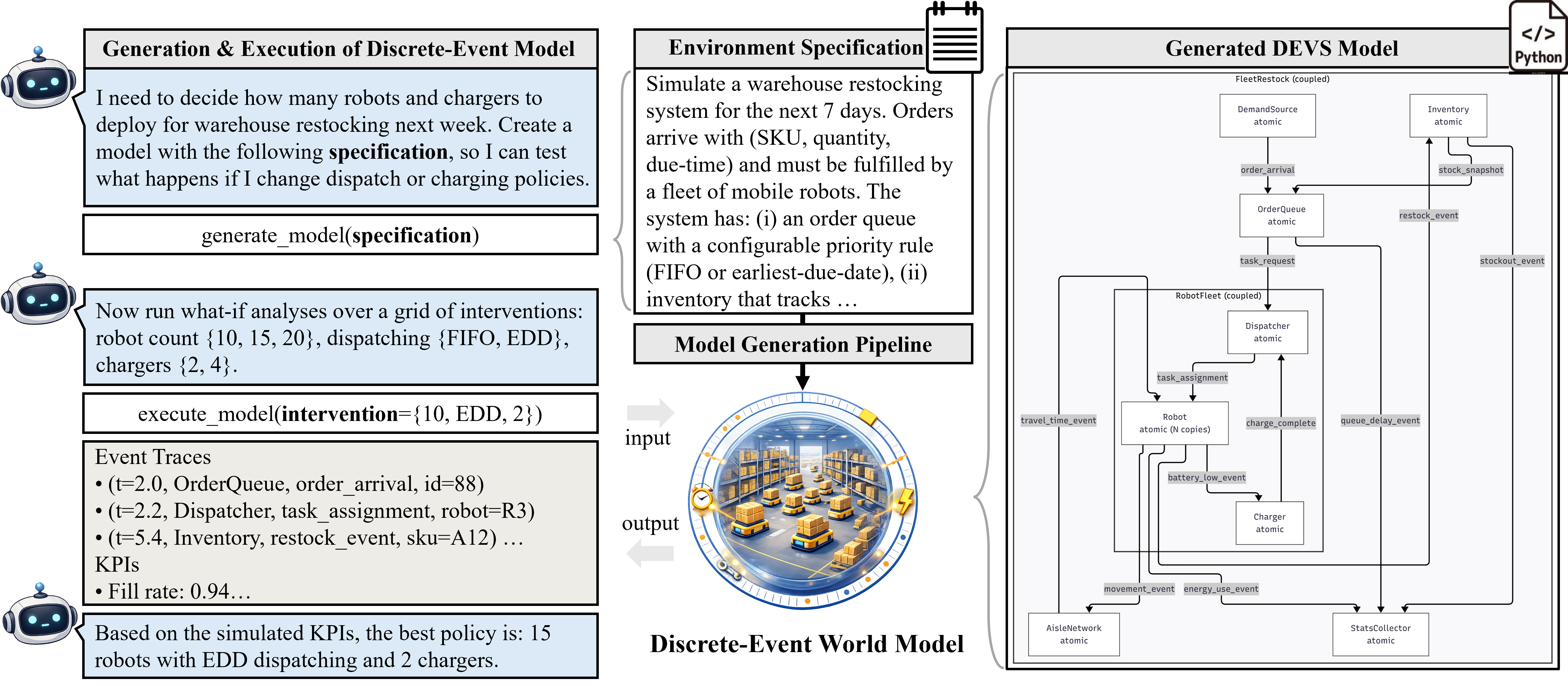
Text to Simulator
Infer a modular simulator with explicit components and interfaces from natural-language requirements, rather than relying on free-form rollouts.
A discrete-event world-model framework for queues, deadlines, logistics, and other event-driven domains
DEVS-Gen turns a natural-language process description into an executable simulator in the DEVS formalism, where system state changes through explicit events such as arrivals, dispatches, delays, and handoffs. The same simulator can then be validated against the specification, reused for what-if analysis, and streamed into an interactive frontend.
Infer a modular simulator with explicit components and interfaces from natural-language requirements, rather than relying on free-form rollouts.
Evaluate generated simulators by checking their emitted event logs against executable operational and behavioral requirements.
Reuse the same simulator for what-if analysis and frontend animation driven by the live trace stream.
A world model is an executable account of how an environment evolves and how actions shape later outcomes. In many high-value domains, that evolution is driven not by continuous physics but by discrete events: arrivals, service delays, resource contention, deadlines, and causal handoffs.
Logistics pipelines, hospital operations, business processes, and lab workflows all fall into this regime. They need models that can answer questions such as what happens next, what breaks under delay, and which intervention is actually better once timing and coordination constraints are enforced.
DEVS-Gen targets this setting using DEVS, a modular modeling and simulation formalism built around components, ports, and event-triggered transitions. By separating structural planning from behavioral synthesis, the framework provides autonomous agents with reusable, explicit simulators that can answer what-if questions and enforce strict coordination constraints for downstream decision support.
A trace-based benchmark is then introduced to rigorously evaluate these generated models. Crucially, because the resulting DEVS simulators are explicit and emit standardized event traces, their behavior becomes fully observable. This visibility enables us to validate the generated code against rules, ensuring temporal and causal consistency. Consequently, the output is not just a black-box prediction, but a verifiable research artifact and a reliable engine for long-horizon planning.
Once a DEVS simulator has been generated, it can be reused for what-if analysis and plan replay under explicit timing, resource, and legality constraints. The two case studies below illustrate that downstream use by comparing a text-only choice with the outcome obtained after executing candidate plans in the same world model.
Read the figure as a downstream-use loop: DEVS-Gen generates a simulator based on the task descriptions given by the user LLM agent; LLM agent feeds candidate actions into the generated simulator; the simulator emits traces and scores; those execution traces reveal consequences that are easy to miss in text alone. The two case cards below summarize that loop for ICU treatment and wet-lab scheduling.
In the ICU example, three 6-hour treatment plans trade off blood-pressure recovery, infection reduction, kidney stress, and fluid-overload risk. Text-only reasoning favors Plan 2, while executing all three plans in the same simulator points instead to Plan 3.
Picked before any plan was executed.
Scores from execution: Plan 1 = -35, Plan 2 = -5, Plan 3 = 15.
In the wet-lab example, three fixed schedules compete under one technician, one incubator, one assay machine, and a delayed biosafety lockout that blocks some preparation steps. Text-only reasoning favors Strategy C, but replaying the schedules in the simulator shows that Strategy B is the best valid schedule.
Looked best before resource and lockout rules were executed.
Composite scores: A = 21, B = 23, C = 22.
DEVS-Gen follows a staged pipeline. It first decides what modules the simulator should contain and how they communicate, then writes the behavior of each module under those interface constraints. Finally, the generated simulator emits a structured event stream, enabling rigorous what-if planning and live visualization in Godot. The Strategic Airlift case below illustrates those stages end to end.
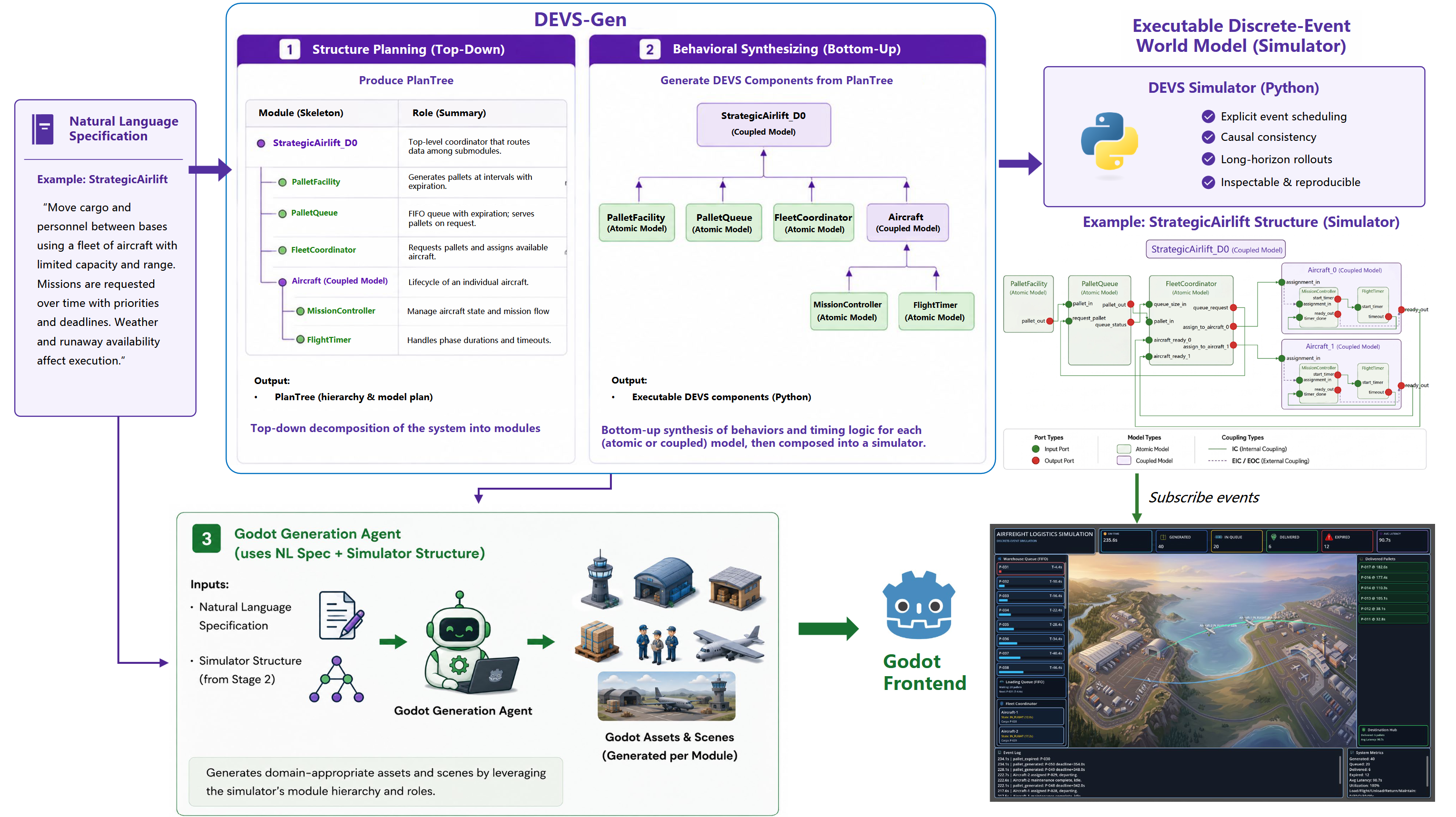
The pipeline fixes structure before behavioral synthesizing, producing an executable simulator that can be benchmarked, inspected, and connected directly to a visualization frontend.
Construct a structural blueprint called a PlanTree, where each node represents a model specified by a ModelPlan. This phase plans the exact port interfaces, coupling connections, and functional descriptions for every node before writing any code.
Guided by the PlanTree, this phase translates the planned functional descriptions into executable code. The core task is designing explicit state machines and event transitions for each component, then wiring the modular structure together.
Because the final output is an explicit structured simulator rather than a black box or spaghetti code, it naturally emits standardized event traces. These traces independently enable what-if interventions, and live visualization.
To illustrate how generation and evaluation intersect, we present an end-to-end deep dive into the Strategic Airlift task from our benchmark. This walkthrough unpacks both the DEVS-Gen pipeline mechanics and our benchmark's testing protocol.
The showcase unfolds in four continuous phases. It begins with the natural-language specification provided by the benchmark test case. Next, based on the specification, the DEVS-Gen pipeline extracts a structural PlanTree and synthesizes an executable simulator. The benchmark evaluate this simulator by automatically scoring its emitted event traces against predefined causality and timing rules. Finally, we demonstrate downstream reusability by driving a real-time Godot animation using the exact same trace stream.
This Godot demo isolates the visual frontend from the simulation backend to prove the generated world model's operational independence and reliability:
flight_departed, cargo_unloaded), the frontend maps these events directly into visual updates of the scene in real time.
This section details our reproducible benchmark for discrete-event world models and summarizes the performance of DEVS-Gen against iterative software agents.
Each benchmark task is packaged so that generation and evaluation are reproducible from observable behavior, rather than tied to one hidden reference implementation.
Measures whether the generated simulator successfully runs, follows the required I/O contract, and emits valid trace logs.
Measures whether the emitted traces satisfy specification-derived behavioral rules about state changes, timing, and causality.
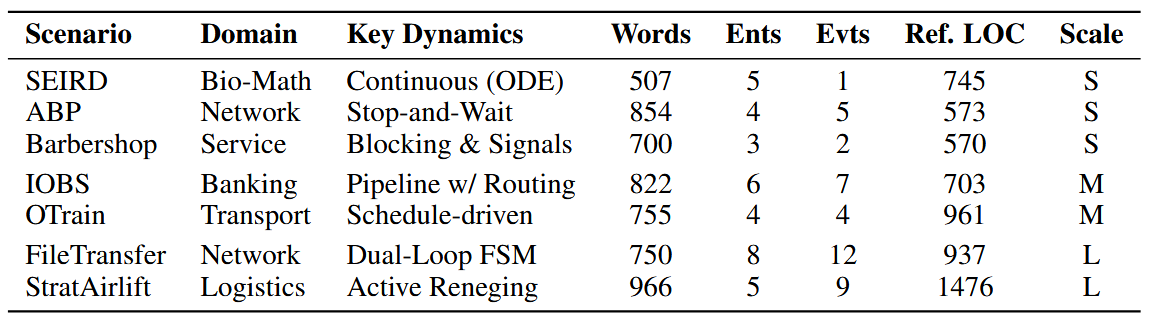
The benchmark spans seven discrete-event scenarios across networking, service operations, banking, transport, logistics, and bio-math dynamics, from compact protocols such as ABP to larger systems such as Strategic Airlift.
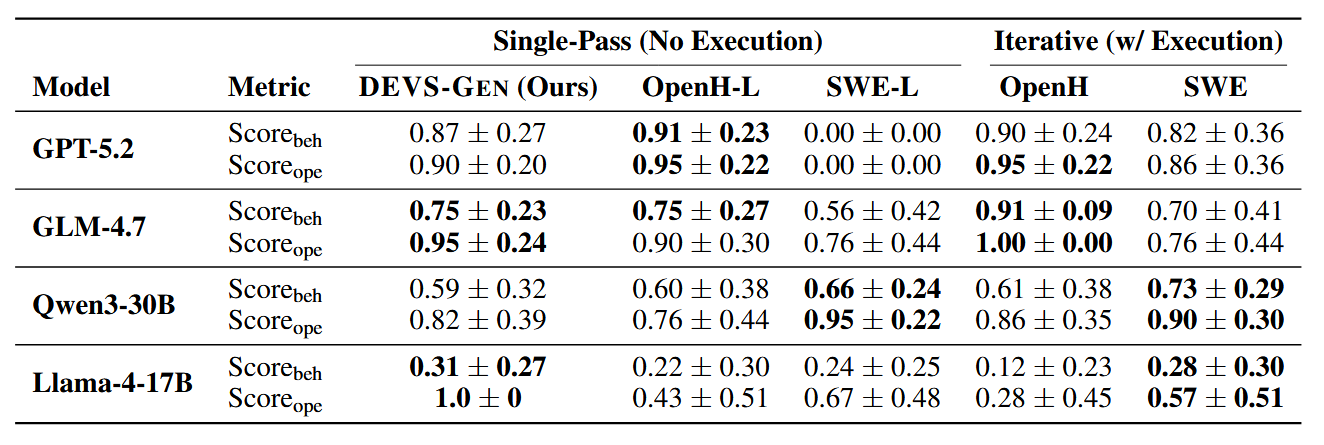
The main result compares DEVS-Gen against iterative coding-agent baselines on the same benchmark, using both operational success and behavioral correctness.
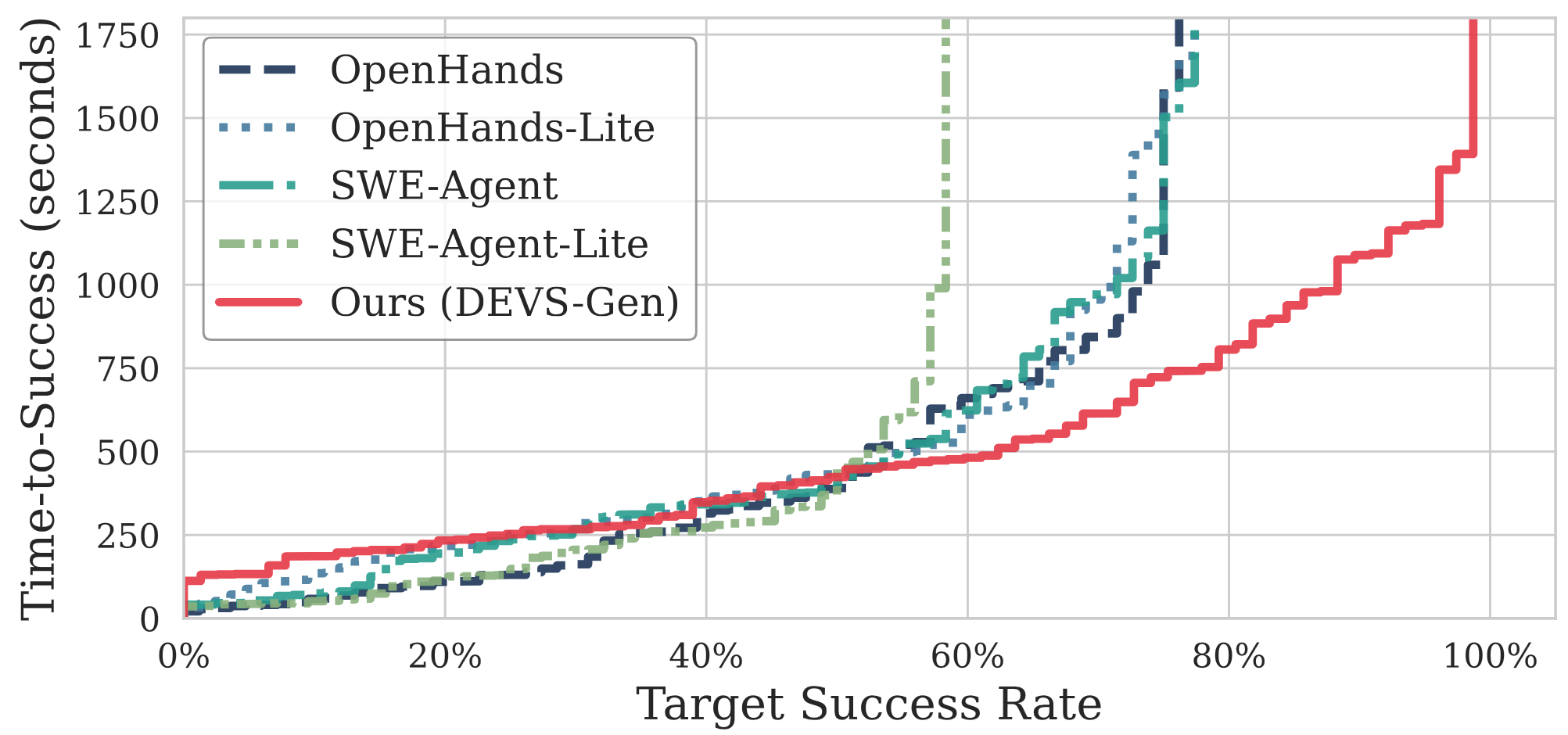
The time-to-success view complements the main benchmark table by showing how quickly methods accumulate solved tasks. DEVS-Gen continues to convert time into completed benchmark cases, while iterative baselines more often stall in debugging-and-repair loops.
The open-source release builds on the HAMLET stack and includes the benchmark suite used in the paper. If you want to reproduce the main workflow, there are two main entry points: devs_app.run for direct model generation and devs_tester for benchmark-style generation and evaluation.
Install the repository, create the Conda environment, and populate the API credentials used by the generator.
git clone https://github.com/czyarl/devs_gen_code.git
cd devs_gen_code
conda create -n hamlet_env python=3.10 -y
conda activate hamlet_env
pip install -r requirements.txt
cp .env.example .env
# Fill in at least one model API key plus the search/scraping keys referenced in the repo README.The direct generation entry point takes a benchmark specification package and produces a simulator. The example below runs the generator on the Alternating Bit Protocol (ABP) benchmark.
python -m devs_app.run \
--mode generate \
--debug_args_file benchmark/ABP/ABP_D1.yaml \
--concur_num 4If you want to inspect the system interactively instead, launch the Gradio interface with python -m devs_app.run.
The experiment harness in devs_tester reproduces the generation-and-evaluation workflow used in the paper benchmarks.
cd devs_tester
python gen_runner.py --list-frameworks
python gen_runner.py --list-benchmarks
python gen_runner.py \
--framework devs_fast_plan \
--model openai/qwen3.6-plus \
--benchmark ABP \
--workspace /path/to/ws
python eval_runner.py \
--benchmark ABP \
--sim_cwd /path/to/generated/project \
--sim_script run.py \
--workspace /path/to/resultsFor the full reproduction setup, including baseline agents, benchmark assets, and experiment configuration, see the GitHub repository linked above.
@misc{chen2026specificationdrivengenerationevaluationdiscreteevent,
title={Specification-Driven Generation and Evaluation of Discrete-Event World Models via the DEVS Formalism},
author={Zheyu Chen and Huiteng Zhuang and Zhuohuan Li and Chuanhao Li},
year={2026},
eprint={2603.03784},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2603.03784},
}